

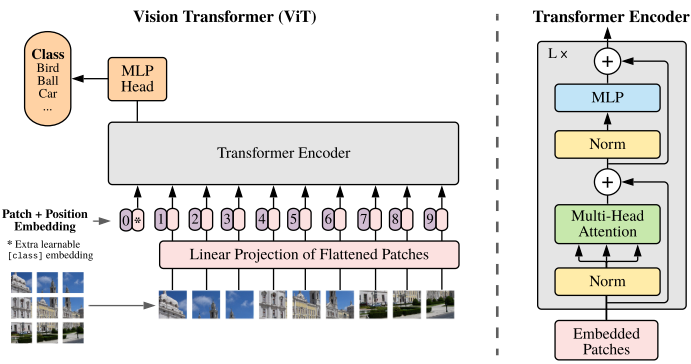
First, we reshape the picture right into a sequence of flattened 2D patches. The code is as follows. image_size means width and peak of picture. The code is as follows.
image_size = 224
channel_size = 3
picture = Picture.open('pattern.png').resize((image_size, image_size))
X = T.PILToTensor()(picture) # Form is [channel_size,image_size,image_size]
patch_size = 16
patches = (
X.unfold(0, channel_size, channel_size)
.unfold(1, patch_size, patch_size)
.unfold(2, patch_size, patch_size)
) # Form is [1,image_size/patch_size,image_size/patch_size,channel_size,patch_size,patch_size]
patches = (
patches.contiguous()
.view(patches.dimension(0), -1, channel_size * patch_size * patch_size)
.float()
) # Form is [1, Number of patches, channel_size*patch_size*patch_size]
Lastly, we create a matrix during which single patch has channel_size*patch_size*patch_size data.
Subsequent, Transformer makes use of fixed latent vector dimension D via all of its layers, so we map the patches to D dimensions with a trainable linear projection (Eq. 1).

We initilize E as follows.
self.E = nn.Parameter(
torch.randn(patch_size * patch_size * channel_size, embedding_dim)
)
We reshape the patches by calculaduring matrix product.
patch_embeddings = torch.matmul(patches, self.E)




{kind=link}