

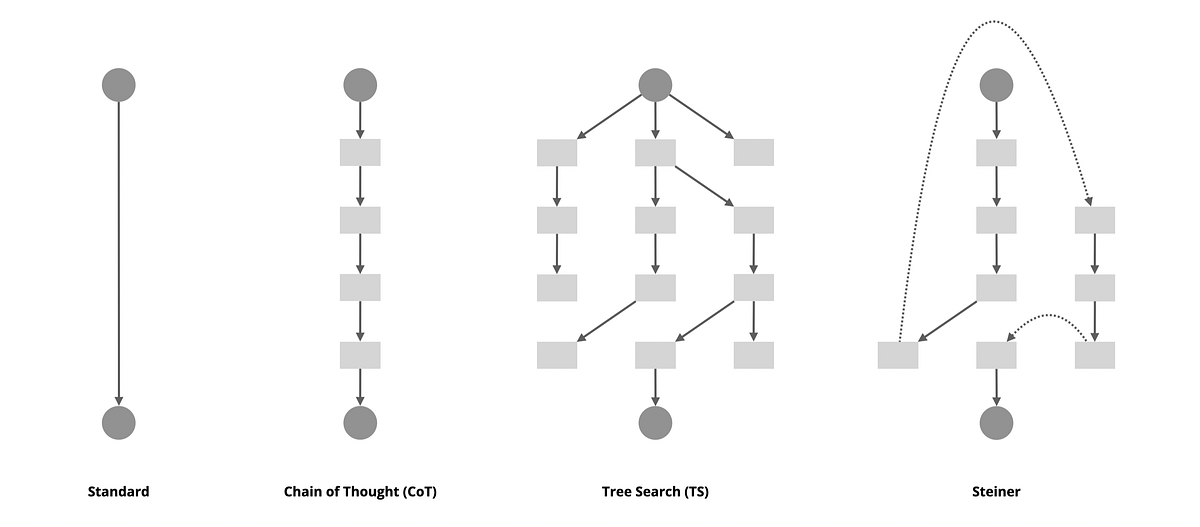
Steiner is a collection of reasoning fashions skilled on artificial information utilizing reinforcement studying. These fashions can discover a number of reasoning paths in an autoregressive method throughout inference and autonomously confirm or backtrack when vital, enabling a linear traversal of the implicit search tree.
🤗 Mannequin Obtain: https://huggingface.co/collections/peakji/steiner-preview-6712c6987110ce932a44e9a6

Steiner is a private curiosity venture by Yichao ‘Peak’ Ji, impressed by OpenAI o1. The final word objective is to breed o1 and validate the inference-time scaling curves. The Steiner-preview model is at the moment a work-in-progress. The rationale for open-sourcing it’s that I’ve discovered automated analysis strategies, based totally on multiple-choice questions, battle to completely replicate the progress of reasoning fashions. In reality, the idea that “the right reply is at all times among the many choices” doesn’t align effectively with real-world reasoning eventualities, because it encourages fashions to carry out substitution-based validation slightly than open-ended exploration. Because of this, I’ve chosen to open-source these intermediate outcomes and, when time permits, to construct in public. This method permits me to share information whereas additionally gathering extra evaluations and suggestions from actual human customers.
⚠️ Disclaimer: Whereas Steiner has been capable of obtain high-quality zero-shot outcomes with out counting on Chain of Thought (CoT) prompting or an agent framework, it has not but replicated the inference-time scaling capabilities demonstrated by o1. In experiments utilizing a specialized logits processor to intervene on reasoning tokens, growing the variety of reasoning steps didn’t enhance efficiency; in reality, it led to a decline in benchmarks similar to MMLU-Professional and GPQA. Because of this, Steiner can not at the moment be thought of a profitable copy of OpenAI o1. There could also be deficiencies in each the coaching strategies and information high quality, so please interpret the outcomes with warning.
In comparison with conventional LLMs, essentially the most notable change in OpenAI o1 is the introduction of reasoning tokens throughout inference, which allows inference-time scaling. This permits the mannequin’s efficiency to enhance by growing the compute funds throughout inference. When discussing inference-time scaling, essentially the most intuitive method is perhaps to introduce tree search or an agentic framework. Nevertheless, after reviewing the (restricted) official data on o1, I observed that a lot of the reported benchmarks are based mostly on cross@1 and majority voting. Moreover, the OpenAI crew has talked about that o1 is a single mannequin, not a system, which piqued my curiosity about how they carried out this exceptional piece of labor.
Though the precise content material of the reasoning tokens has not but been made accessible to builders via the OpenAI API, the token utilization statistics do embody the variety of reasoning tokens (since it’s used for billing builders). With this in thoughts, I designed a easy experiment to make use of o1’s API to research the connection between the variety of completion (together with reasoning) tokens and the entire request time. We all know that if tree search is used, the inference could be as parallel as attainable to reuse cache and maximize GPU utilization, which might end in a sub-linear curve. Nevertheless, the experiment yielded a collection of unpolluted, linear outcomes, with o1-mini exhibiting even much less fluctuation than GPT-4o-mini:

The above experiment led me to a speculation: OpenAI o1 should be a mannequin that performs linear autoregressive decoding, however this doesn’t imply that it doesn’t carry out any “search” in the course of the reasoning section. Think about a search tree — when traversing it, the trail produced is definitely linear. If we might prepare an autoregressive language mannequin that not solely generates reasoning paths however can even validate, backtrack, or swap its method when vital, then within the ultimate case, it might primarily be performing a linear traversal on an implicit search tree throughout the similar context. Whereas this linear traversal might sound inefficient, it has three key benefits over parallel search:
- All prior makes an attempt, whether or not appropriate or incorrect, are saved within the context reminiscence, that means each choice is made with full historic data.
- Implicit backtracking doesn’t require the goal node to exist already throughout the search tree, permitting for extra open-ended exploration.
- From an engineering standpoint, it permits for the reuse of all present, extremely optimized inference infrastructure.

Coaching a mannequin with linear search capabilities isn’t a straightforward process; each information synthesis and mannequin coaching current quite a few challenges.
Firstly, at the moment accessible reasoning datasets consist primarily of artificial Chain of Thought (CoT) or reasoning steps, usually generated by inputting “question-answer” tuples into a robust LLM and asking the mannequin to interrupt down its thought course of. This method signifies that these datasets don’t include cheap backtracking steps. Because of this, fashions skilled on this sort of information primarily be taught shortcuts, or in different phrases, internalize the CoT.
To handle this difficulty, I designed two strategies for information synthesis and augmentation:
- Randomly truncate the reasoning path and conceal the right solutions, permitting a robust LLM to aim ahead reasoning based mostly on the truncated prefix for a sure variety of steps, after which present the right reply to acquire backtracking examples.
- After clustering the steps generated from the earlier step, assign distinctive IDs to every step and assemble a directed acyclic graph (DAG) of all steps for a similar query. Random sampling is then carried out on the DAG to acquire a polynomial variety of reasoning path examples.
By way of the aforementioned strategies (together with appreciable handbook effort and intelligent tips), I in the end obtained 10,000 directed acyclic graphs (DAGs) and sampled 50,000 reasoning path examples with backtracking based mostly on these graphs. Every pattern comprises a median of roughly 1,600 reasoning tokens, which is remarkably near the statistics collected throughout earlier exams of o1/o1-mini! Contemplating the coaching prices, I retained solely these samples with reasoning token counts under 4,096 and a complete of immediate + reasoning + completion tokens under 8,192.
Subsequent, I divided the coaching of the Steiner collection fashions into three levels:
- Continuous Pre-Coaching (CPT): This stage includes coaching on a mixture of peculiar textual content corpora and reasoning paths, permitting the mannequin to familiarize with lengthy reasoning outputs and to preliminarily prepare the embeddings of the 14 newly introduced special tokens. It ought to be famous that exams on some small parameter fashions counsel that this step is perhaps redundant; instantly coaching with a considerable amount of reasoning information in the course of the Supervised Effective-Tuning (SFT) stage appears to yield good representations as effectively. Nevertheless, the 32B CPT was accomplished early on, so I continued to make use of it.
- Supervised Effective-Tuning (SFT): On this stage, coaching is carried out utilizing a chat template, with the objective of instructing the mannequin to mimic the format of reasoning: first, assign a reputation to every step, then output an entire thought, summarize the thought, replicate on the reasoning to this point, and at last resolve whether or not to proceed, backtrack, or finish the reasoning and formally reply the query. You might surprise why an open-source mannequin must generate a abstract like o1, particularly because it doesn’t want to cover its ideas. It’s because I’m making ready for a future Steiner mannequin able to multi-turn dialogue. Theoretically, after coaching, it might be attainable to interchange the whole ideas from earlier conversations with summaries to cut back the pre-fill overhead when the prefix cache can’t be hit. Presently, Steiner has not but been optimized for multi-turn dialogue, and retaining solely summaries might result in adverse few-shot results.
- Reinforcement Studying with Step-Degree Reward (RL): After the primary two levels, the mannequin has discovered to generate and full reasoning paths, nevertheless it nonetheless doesn’t know which decisions are appropriate and environment friendly. If we blindly reward shorter reasoning paths, the mannequin might degrade into shortcut studying, which is simply internalizing the CoT. To handle this, I designed a heuristic reward mechanism: weighting the reward for every step and your complete reasoning path based mostly on the variety of incoming edges e_i, outgoing edges e_o, distance from the unique query d_s, and the gap to the right reply d_e of every node within the DAG. This method guides the mannequin to discover ways to steadiness the breadth and depth of exploration.
The above method could seem easy, however over the previous month, I’ve been fighting out-of-memory (OOM) points and reward hacking each weekend (and on evenings with out time beyond regulation). Lastly, on the thirty eighth day after the discharge of OpenAI o1, I achieved a section of outcomes that I don’t contemplate too embarrassing.

The determine exhibits the efficiency of the Steiner fashions at totally different coaching levels on the GPQA-Diamond dataset. It may be seen that the introduction of the reinforcement studying section resulted in an enchancment of +3.53. When mixed with a logits processor used to constrain the variety of reasoning steps, an optimum configuration can yield an enhancement of +5.56.

The choice to showcase this benchmark is twofold: firstly, as a result of o1/o1-mini has demonstrated important enhancements on this dataset, and secondly, as a result of the contamination scenario of this dataset is comparatively favorable. Moreover, I noticed that Steiner exhibits no important variations in comparison with the baseline on datasets like MMLU, which aligns with OpenAI’s observations relating to o1-mini of their blog, doubtlessly reflecting the restrictions of a 32B mannequin’s world information gained in the course of the pre-training section.
Whereas you will need to acknowledge that the present mannequin’s capabilities nonetheless fall considerably wanting o1-mini and o1, the difficulty lies within the nature of automated analysis benchmarks, that are primarily composed of multiple-choice questions and will not absolutely replicate the capabilities of reasoning fashions. Throughout the coaching section, reasoning fashions are inspired to interact in open-ended exploration of issues, whereas multiple-choice questions function underneath the premise that “the right reply should be among the many choices.” This makes it evident that verifying choices one after the other is a extra environment friendly method. In reality, present massive language fashions have, consciously or unconsciously, mastered this method, no matter whether or not particular prompts are used. Finally, it’s this misalignment between automated analysis and real reasoning necessities that makes me imagine it’s important to open-source the mannequin for actual human analysis and suggestions.
The larger difficulty lies within the inference-time scaling experiments: sadly, after utilizing the logits processor to extend the variety of reasoning steps, Steiner has proven no enhancements on nearly all examined benchmarks, and in some circumstances, efficiency has even declined. There are quite a few speculated causes for this, together with however not restricted to:
- CPT/SFT didn’t allow the mannequin to really grasp lengthy output tokens.
- The heuristic reward design within the RL section failed to assist the mannequin steadiness breadth and depth in reasoning.
- Throughout backtracking, context influences can simply result in confirming incorrect solutions or denying initially appropriate ones.
- The strategy of forcibly modifying logits to extend reasoning steps is simply too blunt.
- … …
All in all, this would be the main focus of my future work.
- Steiner’s present post-training information doesn’t embody examples for multi-turn dialogues. The perfect-performing model of the Steiner mannequin (based mostly on Qwen2.5–32B) lacks the power to deal with multi-turn conversations. The open-source Steiner-preview mannequin (based mostly on Qwen2.5–32B-Instruct) is appropriate with chat codecs however remains to be not advisable for multi-turn dialogues.
- Just like OpenAI o1–2024–09–12, Steiner additionally doesn’t suggest using customized system prompts or modifications to sampling parameters similar to temperature. Steiner has not but been skilled on a various set of system prompts, and altering different parameters might result in errors within the formatting of reasoning tokens.
- The language composition of Steiner’s post-training information is roughly 90% English and 10% Chinese language, however in the course of the reasoning path information augmentation course of, nearly solely English was used. Due to this fact, whereas the mannequin’s last responses exhibit a sure diploma of language following capacity, the reasoning tokens might predominantly be generated in English.
As for the origin of the identify Steiner, why not ask the mannequin itself?
🧑🏻💻 What’s the origin of your identify?
💬 My identify, “Steiner,” is impressed by the protagonist’s capacity “Studying Steiner” from the visible novel and anime *Steins;Gate*. This capacity permits the character to retain recollections throughout a number of world strains, which aligns with my capabilities of exploring totally different reasoning paths and retaining data throughout them.




{kind=link}