

The use of LLMs has become inevitable, but relying solely on cloud-based APIs can be limiting due to cost, reliance on third parties, and potential privacy concerns. That’s where self-hosting an LLM for inference comes in.
| Tool | Best For | |
|---|---|---|
|
1. |

Ollama |
Integrations (wide compatibility) |
|
2. |

vLLM |
Developers (high performance) |
|
3. |

AnythingLLM |
RAG applications in local |
|
4. |

LM Studio |
Beginner-friendly experimentation |
1.
Integrations (wide compatibility)
2.
Developers (high performance)
3.
RAG applications in local
4.
Beginner-friendly experimentation
LLM Compatibility Calculator
You can use the calculator to estimate the RAM needed based on model parameters, quantization method, and your hardware specs. Enter your configuration details below to instantly check compatibility.
The available quantization methods and precision bits for vendors are taken from Hugging Face transformers library documentation.
You can read more about the optimization techniques to host LLMs locally.
Ollama
Ollama is an open-source tool that simplifies running LLMs locally on macOS, Linux, and Windows. It bundles models and configurations, making setup straightforward for various popular LLMs. Ollama prioritizes ease of use and privacy via offline operation and supports integrations with developer tools like LangChain and user-friendly interfaces like Open WebUI, which provides a chat-based graphical experience for interacting with the locally hosted models.
It allows users and developers to easily run and interact with LLMs on their personal machines, including multimodal models, making it ideal for local development and privacy-conscious usage.
vLLM
vLLM is a high-performance engine designed for fast and memory-efficient large language model serving. It uses techniques like PagedAttention and continuous batching to maximize throughput and reduce memory requirements during inference.
It supports distributed execution and various hardware (NVIDIA, AMD, Intel) and offers an OpenAI-compatible API for integration. vLLM targets developers and researchers focused on optimizing LLM deployment in production environments. It excels at scalable, high-speed model serving.
AnythingLLM
AnythingLLM is an open-source desktop tool for running large language models (LLMs) on macOS, Windows, and Linux. It enables users to apply RAG to process documents like PDFs, CSVs, and codebases, retrieving relevant information for chat-based interactions without coding.
It operates offline by default for privacy and integrates RAG to enhance responses using user-provided data. AnythingLLM suits developers and beginners exploring document-driven LLM use cases, with additional support for AI agents and customization through a community hub.
LM Studio
LM Studio is a beginner-friendly desktop application for discovering, downloading, and experimenting with large language models locally across macOS, Windows, and Linux. It features an intuitive graphical interface for managing models from sources like Hugging Face and interacting via a chat UI or a local server.
LM Studio simplifies experimentation with features like offline RAG and leverages efficient backends like llama.cpp and MLX. It caters primarily to beginners and developers wanting an easy-to-use environment for exploring local LLMs.
Open-source large language models
Open-source LLMs are models whose architecture and model files (containing weights, often with billions of more parameters) are publicly available, allowing anyone to download, modify, and use them.
Platforms like Hugging Face serve as central repositories, making it easy to access these models for tasks like building a self-hosted LLM solution. Often packaged within a container image for easier deployment, these models enable users to run model inference directly on their own hardware, offering greater control and flexibility compared to closed-source alternatives.
Advantages of self-hosted LLMs
- Full Control & Deeper Customization: Host models on your own hardware to gain complete command over your LLM applications, enabling deeper customization for fine-tuning beyond standard APIs.
- Enhanced Data Security: Keep your data, especially sensitive data, secure within your own systems, significantly improving data security as information doesn’t need to leave your control.
- Cost-Effectiveness: Achieve potential long-term cost savings by utilizing your own infrastructure and leveraging open models, avoiding recurring cloud subscription fees.
- Flexibility with Open Models: Take advantage of a growing ecosystem of open models that can be deployed as self-hosted models without vendor lock-in.
- User-Friendly Management: Many self-hosting offers provide tools like a web UI to simplify management and interaction with your deployed models.
Disadvantages of self-hosted LLMs
- Significant Hardware Investment: Running self-hosted models effectively demands powerful hardware, especially systems with large amounts of expensive GPU memory, representing a major upfront cost and potential infrastructure challenge.
- Complex LLM Deployment: Setting up open-source models requires significant technical expertise in configuration, dependency management, and troubleshooting; it’s rarely a single command process.
- Limited Access to Proprietary Models: While you can deploy open-source models, self-hosting typically excludes access to the latest, cutting-edge proprietary models (like GPT-4.5, Grok 3, etc.), which are often only available via managed hosted LLM APIs; these other models remain inaccessible on your own system.
- Performance Optimization Burden: Achieving better performance and acceptable response times necessitates continuous monitoring, tuning, and optimization of resource usage, a responsibility that falls entirely on the user, unlike with managed services.
Optimizing LLMs for self-hosting
Running AI models like large language models on your own hardware can be challenging due to their size and resource needs, but several techniques help manage their model weights effectively. Methods such as quantization, multi-GPU support, and off-loading improve efficiency, making it possible to host these models at home or work.
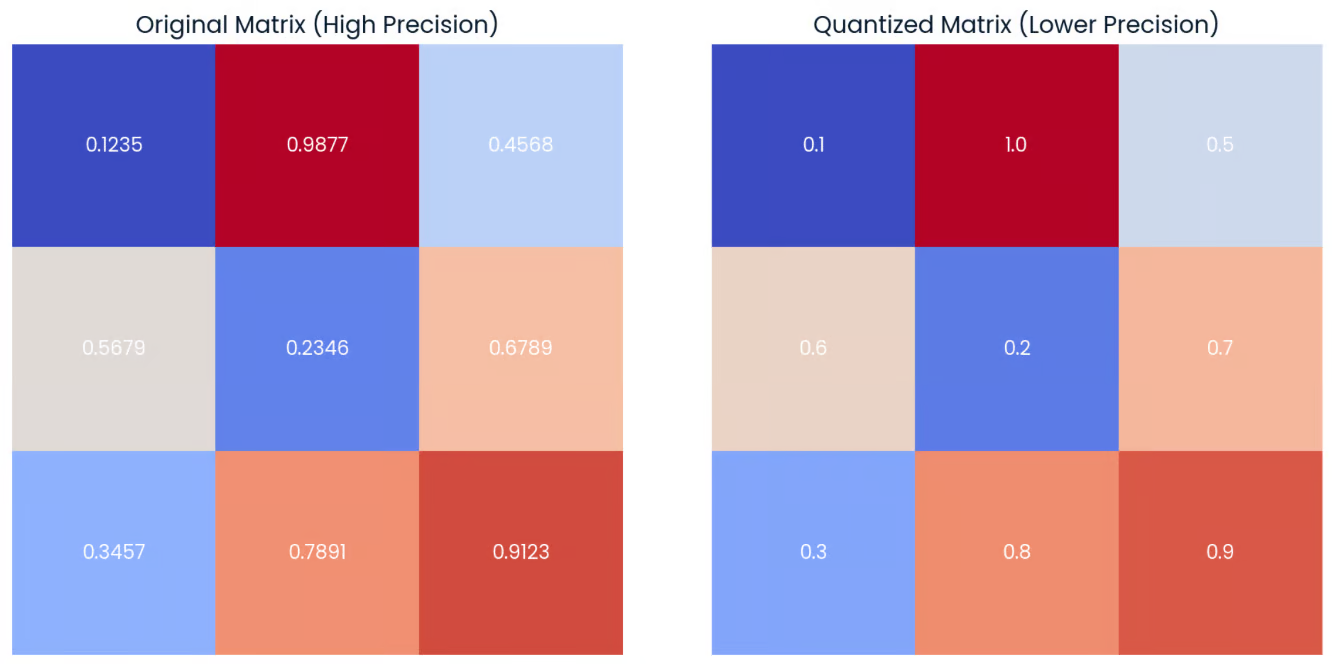
Quantization
Quantization, as illustrated in the figure below, often involves reducing the precision of model weights in machine learning by converting high-precision values (like 0.9877 in the Original Matrix) to lower-precision representations (like 1.0 in the Quantized Matrix). This process decreases model size and can speed up computation, albeit with a potential loss in accuracy.
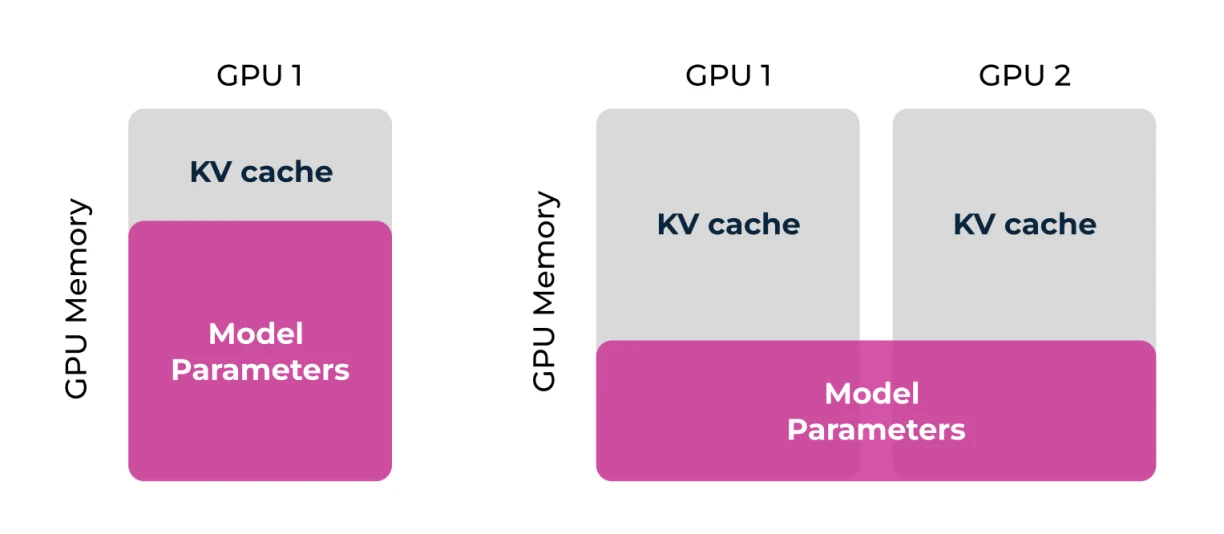
Multi GPU support
As illustrated in the figure, distributing the large ‘Model Parameters’ across multiple GPUs (GPU 1 and GPU 2) allows users to run larger, more capable models on hardware they manage, overcoming single-GPU memory limitations and making self-hosting feasible. This effectively pools resources, optimizing the use of available hardware to meet the demanding requirements of modern LLMs.
Off-loading
Parameter off-loading optimizes LLMs for self-hosting by addressing the limited memory available on consumer GPUs. This technique involves dynamically moving parts of the large model, such as inactive “expert” parameters in MoE models, between the fast GPU memory and slower system RAM. By doing this, offloading allows users to run large, powerful models on accessible hardware that wouldn’t otherwise have enough dedicated GPU memory, making self-hosting feasible.
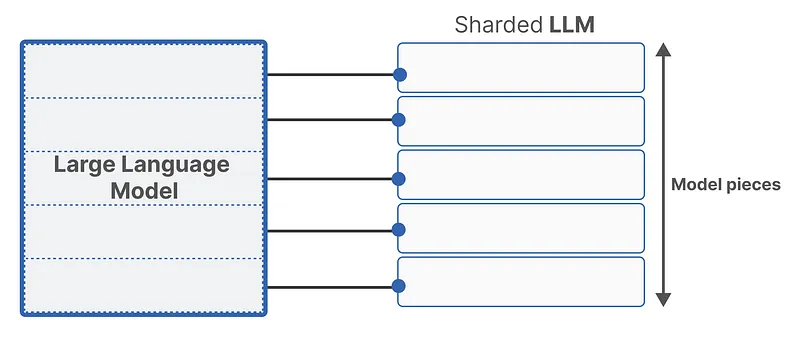
Model sharding
Sharding, as illustrated in the image below, divides the complete “Large Language Model” into several smaller, more manageable “Model pieces.” This technique allows the distribution of these pieces across multiple devices (like GPUs) or even different types of memory within a self-hosted setup. By breaking down the model, sharding overcomes the memory limitations of individual hardware components, making it possible to run large models on personally managed infrastructure.
FAQ about self-hosted LLMs
What is a self-hosted LLM?
A self-hosted LLM is a large language model used for LLM applications that runs entirely on hardware you control (like your personal computer or private server) rather than relying on a third-party cloud service.
What are the techniques for running LLMs locally?
Techniques include using frameworks like llama.cpp, libraries like Hugging Face transformers, user-friendly apps (Ollama, LM Studio), model quantization (e.g., GGUF, GPTQ) to reduce resource needs, model parallelism to distribute large models across multiple devices, and optimized inference engines (like vLLM).
Is it possible to process multiple requests on a self-hosted LLM?
Yes, tools like vLLM, Ollama, and LM Studio can run local servers capable of handling multiple (often concurrent) requests. This is similar to how cloud APIs operate, often using batching for efficiency.
Do I need to request access for self-hosted LLMs?
No, you don’t need external access permission or API keys from a provider for self-hosted llm. Since you host it yourself, you have direct access; you might optionally set up your own authentication for your local server if needed.




{kind=link}