


Lung most cancers is the main explanation for cancer-related deaths globally with 1.8 million deaths reported in 2020. Late prognosis dramatically reduces the possibilities of survival. Lung cancer screening by way of computed tomography (CT), which supplies an in depth 3D picture of the lungs, has been proven to cut back mortality in high-risk populations by a minimum of 20% by detecting potential indicators of cancers earlier. Within the US, screening includes annual scans, with some international locations or instances recommending kind of frequent scans.
The United States Preventive Services Task Force lately expanded lung most cancers screening suggestions by roughly 80%, which is predicted to extend screening entry for ladies and racial and ethnic minority teams. Nonetheless, false positives (i.e., incorrectly reporting a possible most cancers in a cancer-free affected person) may cause anxiousness and result in pointless procedures for sufferers whereas rising prices for the healthcare system. Furthermore, effectivity in screening numerous people might be difficult relying on healthcare infrastructure and radiologist availability.
At Google we’ve got beforehand developed machine learning (ML) models for lung cancer detection, and have evaluated their skill to routinely detect and classify areas that present indicators of potential most cancers. Efficiency has been proven to be similar to that of specialists in detecting potential most cancers. Whereas they’ve achieved excessive efficiency, successfully speaking findings in real looking environments is important to comprehend their full potential.
To that finish, in “Assistive AI in Lung Cancer Screening: A Retrospective Multinational Study in the US and Japan”, revealed in Radiology AI, we examine how ML fashions can successfully talk findings to radiologists. We additionally introduce a generalizable user-centric interface to assist radiologists leverage such fashions for lung most cancers screening. The system takes CT imaging as enter and outputs a most cancers suspicion score utilizing 4 classes (no suspicion, most likely benign, suspicious, extremely suspicious) together with the corresponding areas of curiosity. We consider the system’s utility in enhancing clinician efficiency by way of randomized reader research in each the US and Japan, utilizing the native most cancers scoring techniques (Lung-RADSs V1.1 and Sendai Score) and picture viewers that mimic real looking settings. We discovered that reader specificity will increase with mannequin help in each reader research. To speed up progress in conducting comparable research with ML fashions, we’ve got open-sourced code to course of CT pictures and generate pictures appropriate with the picture archiving and communication system (PACS) utilized by radiologists.
Creating an interface to speak mannequin outcomes
Integrating ML fashions into radiologist workflows includes understanding the nuances and targets of their duties to meaningfully assist them. Within the case of lung most cancers screening, hospitals observe varied country-specific pointers which can be frequently up to date. For instance, within the US, Lung-RADs V1.1 assigns an alpha-numeric score to point the lung most cancers threat and follow-up suggestions. When assessing sufferers, radiologists load the CT of their workstation to learn the case, discover lung nodules or lesions, and apply set pointers to find out follow-up selections.
Our first step was to enhance the previously developed ML models by way of further coaching knowledge and architectural enhancements, together with self-attention. Then, as an alternative of concentrating on particular pointers, we experimented with a complementary manner of speaking AI outcomes impartial of pointers or their specific variations. Particularly, the system output gives a suspicion score and localization (areas of curiosity) for the person to contemplate together with their very own particular pointers. The interface produces output pictures immediately related to the CT examine, requiring no adjustments to the person’s workstation. The radiologist solely must overview a small set of further pictures. There isn’t a different change to their system or interplay with the system.
 |
| Instance of the assistive lung most cancers screening system outputs. Outcomes for the radiologist’s analysis are visualized on the placement of the CT quantity the place the suspicious lesion is discovered. The general suspicion is displayed on the prime of the CT pictures. Circles spotlight the suspicious lesions whereas squares present a rendering of the identical lesion from a unique perspective, referred to as a sagittal view. |
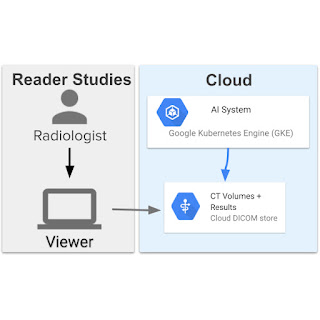
The assistive lung most cancers screening system contains 13 fashions and has a high-level structure much like the end-to-end system utilized in prior work. The fashions coordinate with one another to first phase the lungs, get hold of an total evaluation, find three suspicious areas, then use the data to assign a suspicion score to every area. The system was deployed on Google Cloud utilizing a Google Kubernetes Engine (GKE) that pulled the pictures, ran the ML fashions, and supplied outcomes. This permits scalability and immediately connects to servers the place the pictures are saved in DICOM stores.
 |
| Define of the Google Cloud deployment of the assistive lung most cancers screening system and the directional calling movement for the person elements that serve the pictures and compute outcomes. Pictures are served to the viewer and to the system utilizing Google Cloud providers. The system is run on a Google Kubernetes Engine that pulls the pictures, processes them, and writes them again into the DICOM retailer. |
Reader research
To guage the system’s utility in enhancing medical efficiency, we performed two reader research (i.e., experiments designed to evaluate medical efficiency evaluating professional efficiency with and with out assistance from a expertise) with 12 radiologists utilizing pre-existing, de-identified CT scans. We introduced 627 difficult instances to six US-based and 6 Japan-based radiologists. Within the experimental setup, readers have been divided into two teams that learn every case twice, with and with out help from the mannequin. Readers have been requested to use scoring pointers they usually use of their medical apply and report their total suspicion of most cancers for every case. We then in contrast the outcomes of the reader’s responses to measure the affect of the mannequin on their workflow and selections. The rating and suspicion degree have been judged in opposition to the precise most cancers outcomes of the people to measure sensitivity, specificity, and area under the ROC curve (AUC) values. These have been in contrast with and with out help.
 |
| A multi-case multi-reader examine includes every case being reviewed by every reader twice, as soon as with ML system help and as soon as with out. On this visualization one reader first evaluations Set A with out help (blue) after which with help (orange) after a wash-out interval. A second reader group follows the alternative path by studying the identical set of instances Set A with help first. Readers are randomized to those teams to take away the impact of ordering. |
The flexibility to conduct these research utilizing the identical interface highlights its generalizability to utterly totally different most cancers scoring techniques, and the generalization of the mannequin and assistive functionality to totally different affected person populations. Our examine outcomes demonstrated that when radiologists used the system of their medical analysis, they’d an elevated skill to appropriately determine lung pictures with out actionable lung most cancers findings (i.e., specificity) by an absolute 5–7% in comparison with once they didn’t use the assistive system. This probably implies that for each 15–20 sufferers screened, one could possibly keep away from pointless follow-up procedures, thus decreasing their anxiousness and the burden on the well being care system. This could, in flip, assist enhance the sustainability of lung most cancers screening packages, notably as more people become eligible for screening.
 |
| Reader specificity will increase with ML mannequin help in each the US-based and Japan-based reader research. Specificity values have been derived from reader scores from actionable findings (one thing suspicious was discovered) versus no actionable findings, in contrast in opposition to the true most cancers final result of the person. Beneath mannequin help, readers flagged fewer cancer-negative people for follow-up visits. Sensitivity for most cancers constructive people remained the identical. |
Translating this into real-world affect by way of partnership
The system outcomes display the potential for fewer follow-up visits, diminished anxiousness, as properly decrease total prices for lung most cancers screening. In an effort to translate this analysis into real-world medical affect, we’re working with: DeepHealth, a number one AI-powered well being informatics supplier; and Apollo Radiology International a number one supplier of Radiology providers in India to discover paths for incorporating this method into future merchandise. As well as, we wish to assist different researchers finding out how greatest to combine ML mannequin outcomes into medical workflows by open sourcing code used for the reader examine and incorporating the insights described on this weblog. We hope that this may assist speed up medical imaging researchers seeking to conduct reader research for his or her AI fashions, and catalyze translational analysis within the discipline.
Acknowledgements
Key contributors to this undertaking embrace Corbin Cunningham, Zaid Nabulsi, Ryan Najafi, Jie Yang, Charles Lau, Joseph R. Ledsam, Wenxing Ye, Diego Ardila, Scott M. McKinney, Rory Pilgrim, Hiroaki Saito, Yasuteru Shimamura, Mozziyar Etemadi, Yun Liu, David Melnick, Sunny Jansen, Nadia Harhen, David P. Nadich, Mikhail Fomitchev, Ziyad Helali, Shabir Adeel, Greg S. Corrado, Lily Peng, Daniel Tse, Shravya Shetty, Shruthi Prabhakara, Neeral Beladia, and Krish Eswaran. Because of Arnav Agharwal and Andrew Sellergren for his or her open sourcing assist and Vivek Natarajan and Michael D. Howell for his or her suggestions. Honest appreciation additionally goes to the radiologists who enabled this work with their picture interpretation and annotation efforts all through the examine, and Jonny Wong and Carli Sampson for coordinating the reader research.



{kind=link}