

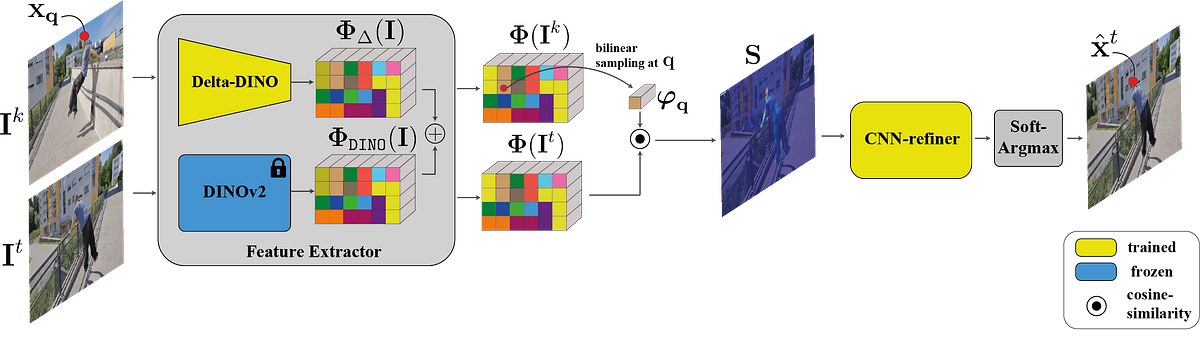
Abstract
- Context: Modern vision systems struggle with limited labels and domain shift in real-world environments.
- Problem: Supervised pipelines collapse when annotation is scarce or inconsistent.
- Approach: Utilize DINO/DINOv2 as self-supervised feature backbones, supplemented by a lightweight supervised head.
- Results: Linear probes achieve ~97% CV and ~96.5% test accuracy; embeddings form clean semantic clusters.
- Conclusion: Self-supervised vision is production-ready — labels are optional, not foundational.
Keywords: self-supervised vision backbone; vision transformer architecture; remote sensing image analysis; robotics visual inspection; label-free computer vision trend
What if the best vision features you ever trained came from a model that never saw a single label?
In the rush toward ever-larger supervised datasets and increasingly complex architectures, it’s easy to forget a stubborn fact every practitioner eventually confronts: labels don’t scale. They slow teams down, inject bias, and limit the generalization ceiling of otherwise powerful models. And yet, organizations continue to invest time in annotation pipelines because they believe, “that’s the only way to train strong vision models.” Except it isn’t.



{kind=link}