


Agentic Document Extraction (ADE) is a specialized form of Optical Character Recognition (OCR) that extracts data from various file types. It combines document processing, data retrieval, structured output generation, and automation to streamline knowledge work.
ADE stands out from traditional OCR by its ability to recognize complex document structures, such as tables, flowcharts, and images. This makes it more advanced than conventional Intelligent Document Processing (IDP) and Retrieval-Augmented Generation (RAG) methods.
Our benchmark revealed that LandingAI is the most capable tool for agentic document extraction, scoring 63 out of 100.
*Docsumo’s off-the-shelf agentic document extraction does not provide a tool for flowchart extraction. The product can be trained for various document extraction processes; however, our benchmark is based on off-the-shelf models. Therefore, Docsumo did not gain scores from flowchart extraction.
We evaluated the tools using three metrics for flowchart evaluation and four metrics for table evaluation. You can find the details in our agentic document extraction benchmark methodology.
LandingAI
LandingAI left traditional approaches behind and used OCR in different areas. Their document processing is not limited to one type of data extraction. They claim that their agentic document extraction tool can extract complicated images and “fill in the blanks” when needed. The tool can be used in the LandingAI playground or through API calls.
Distinguishing feature: It can extract complicated and mixed data(text and table on the same page) without any prompting.
Mistral OCR
Mistral AI has introduced Mistral OCR to improve document understanding. This tool accurately processes a range of document elements, including text, tables, and images, while maintaining their structure and hierarchy. It supports multiple formats and delivers results in markdown format for easy parsing and rendering.
Distinguishing feature: It is explicitly optimized for multimodal Retrieval-Augmented Generation (RAG) integrations, preserving document structure with markdown-formatted output ideal for downstream AI workflows.
Anthropic Claude Sonnet 3.7
Anthropic’s Claude 3.7 Sonnet is a cutting-edge AI model with hybrid reasoning capabilities, enabling it to alternate between quick responses and in-depth, step-by-step analysis. This model can process PDFs of up to 100 pages, analyzing both text and visual elements, such as images, charts, and graphics. Its extended thinking mode is ideal for complex document analysis tasks, including coding and mathematical reasoning.
Distinguishing feature: It supports deep hybrid reasoning, combining rapid-response analysis with meticulous step-by-step logic, which is beneficial for comprehensive understanding and extraction from extensive documents.
OpenAI o3-mini
OpenAI’s o3-mini is a cost-effective reasoning model known for its ability to tackle tasks that require step-by-step problem-solving, such as coding and mathematical reasoning. It allows for file and image uploads, which enhance its document analysis capabilities. Users have reported successful optical character recognition (OCR) processing of PDFs with o3-mini, emphasizing its capacity to extract relevant sections based on user prompts.
Distinguishing feature: Specially designed as a cost-effective model emphasizing iterative, step-by-step reasoning, which makes it uniquely effective in structured data extraction tasks involving logical or computational workflows.
Docsumo
Docsumo provides an intelligent document processing platform that includes more than 30 pre-trained AI models for extracting data from various documents, such as bank statements and invoices. The platform offers features like auto-classification, document analytics, metadata extraction, and export options in JSON, CSV, and Excel formats. Additionally, Docsumo integrates with tools like Salesforce and QuickBooks, which helps streamline workflows and enhance efficiency.
Distinguishing feature: It provides specialized user-driven training, enabling the creation of custom AI extraction models tailored specifically for individual datasets.
Pricing
You can see the pricing for the tools we have examined. LLMs operate on API pricing, which has a few factors to consider, such as input and output being priced separately. In contrast, OCR tools typically use pay-as-you-go pricing per page. We assumed that each page contains approximately 600 tokens for our pricing calculations. This conversion was made to ensure consistent pricing for you.
*Docsumo offers annual subscriptions that are billed monthly for a constant number of pages per year.
Agentic document extraction involves using AI agents to identify, interpret, and extract specific information from documents independently with minimal human intervention. Unlike traditional methods, which often depend on rigid templates or manual tagging, agentic extraction employs intelligent systems that can reason and adapt dynamically. This approach significantly enhances the speed, accuracy, and efficiency of processing large volumes of complex documents.
Limitations of traditional OCR
Traditional OCR technology is effective for extracting text from structured documents. However, it faces significant challenges when processing complex, unstructured, or semi-structured documents. Common limitations include inaccuracies caused by variations in fonts, handwriting, poor image quality, and inconsistent formatting. Additionally, traditional OCR lacks contextual understanding, which can lead to misinterpretation of data. As a result, manual review or extensive post-processing is often required to correct errors, creating inefficiencies in the workflow.
Agentic Document Extraction (ADE) is a relatively new concept, and as such, there aren’t many real-life examples available. However, it has the potential to be applied in various areas. We have identified four examples where ADE can be directly implemented to streamline processes compared to traditional document extraction methods.
1. Financial services: Automated invoice processing
In the financial sector, organizations handle vast numbers of invoices daily. Agentic document extraction automates the capture and validation of invoice data, ensuring accuracy and compliance. This automation accelerates payment cycles, improves cash flow management, and strengthens supplier relationships.
2. Healthcare: Streamlining patient intake forms
Healthcare providers manage numerous patient intake forms, which can be time-consuming to process manually. Agentic document extraction captures data from these forms, facilitating efficient patient onboarding and reducing administrative burdens. This improves patient experiences and allows medical staff to focus more on patient care.
3. Customer Service: Support through document analysis
Customer service departments frequently manage inquiries that involve detailed documents like contracts or service agreements. Agentic document extraction allows for the analysis and extraction of relevant sections from these documents, enabling support agents to provide accurate and timely responses. This technology enhances the quality of responses and reduces the amount of time agents spend searching for information.
4. Insurance: Processing of handwritten insurance claims
Insurance companies frequently receive handwritten claims that require extensive manual processing. Utilizing advanced document extraction technology can accurately interpret handwritten text, extract relevant data, and integrate it into digital systems. This process significantly reduces both processing time and errors. For example, Appian provides solutions that automate data extraction from handwritten insurance claims, streamlining workflows and enhancing overall efficiency.
ADE benchmark methodology
We have gathered our dataset from Huggingface datasets with low download numbers so that the images we use are not already in the training set of LLMs. We have used 60 images, 30 of which contain flowcharts of various complexity.
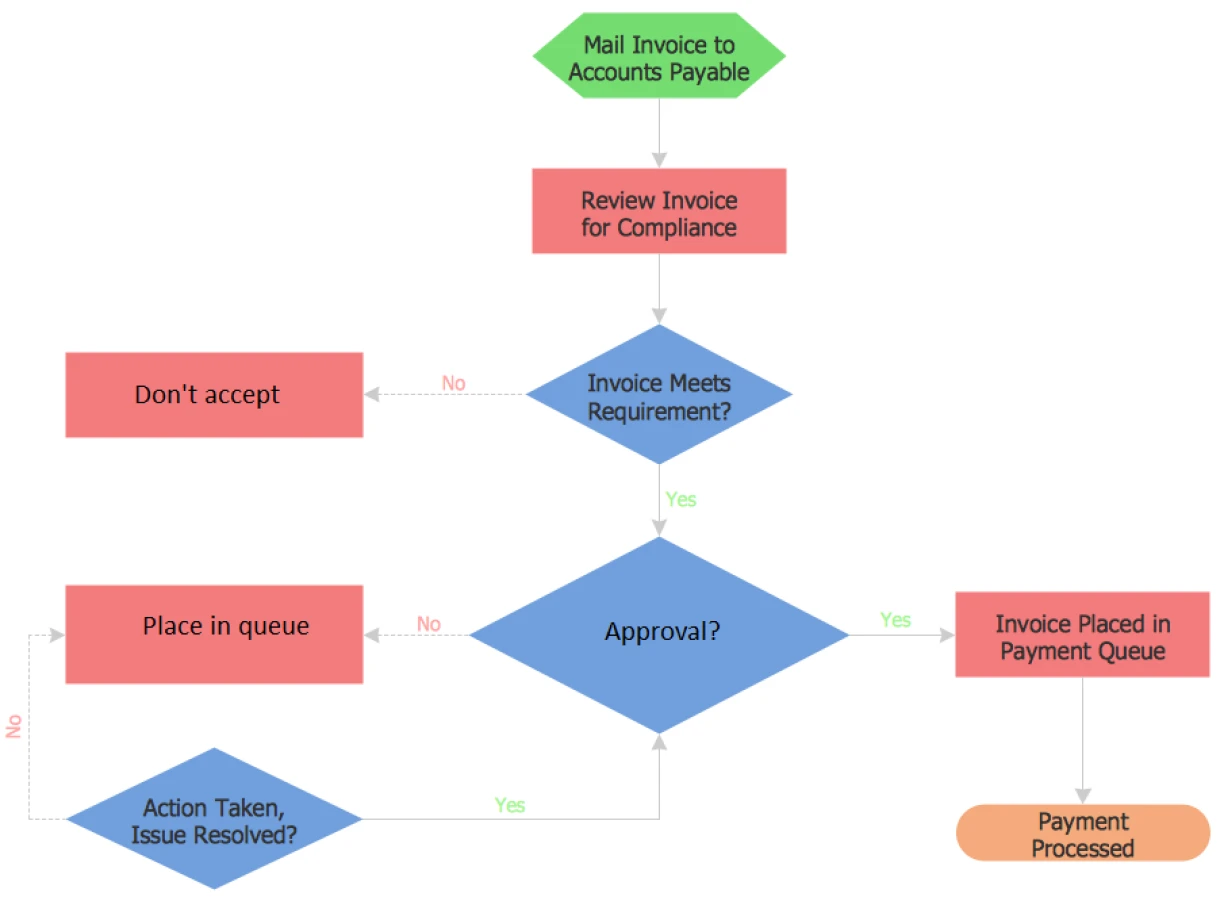
Image 1. An example of flowcharts in our dataset
The flowcharts have been uploaded to the tools as PNG images, and the outputs are taken as JSON files. There are 3 metrics we have used for measuring the performance:
- Node accuracy: Measures the proportion of ground-truth nodes (labels/aliases) the extracted text mentions. For example, if the ground truth lists 10 nodes and the model successfully references 8, the node accuracy is 0.80 (80%).
- Edge accuracy: Verifies if the extracted text accurately identifies the relationships between nodes (e.g., “Node A → Node B”). For instance, if there are 5 true edges and the model’s text only reveals 3 correctly, the edge accuracy is calculated as 3/5 = 0.60 (60%).
- Decision accuracy: This is a similar concept to edge accuracy but for decision points (e.g., yes/no branches). If there are four decision points and the model identifies all four, the decision accuracy is 100%.
The composite score is the simple average of node, edge, and decision accuracies, providing an overall measure of how well the extracted text aligns with all flowchart elements.
The second dataset contains 30 PNG images with tables that are taken from various industry documents; the processing of the dataset is the same as the flowcharts.
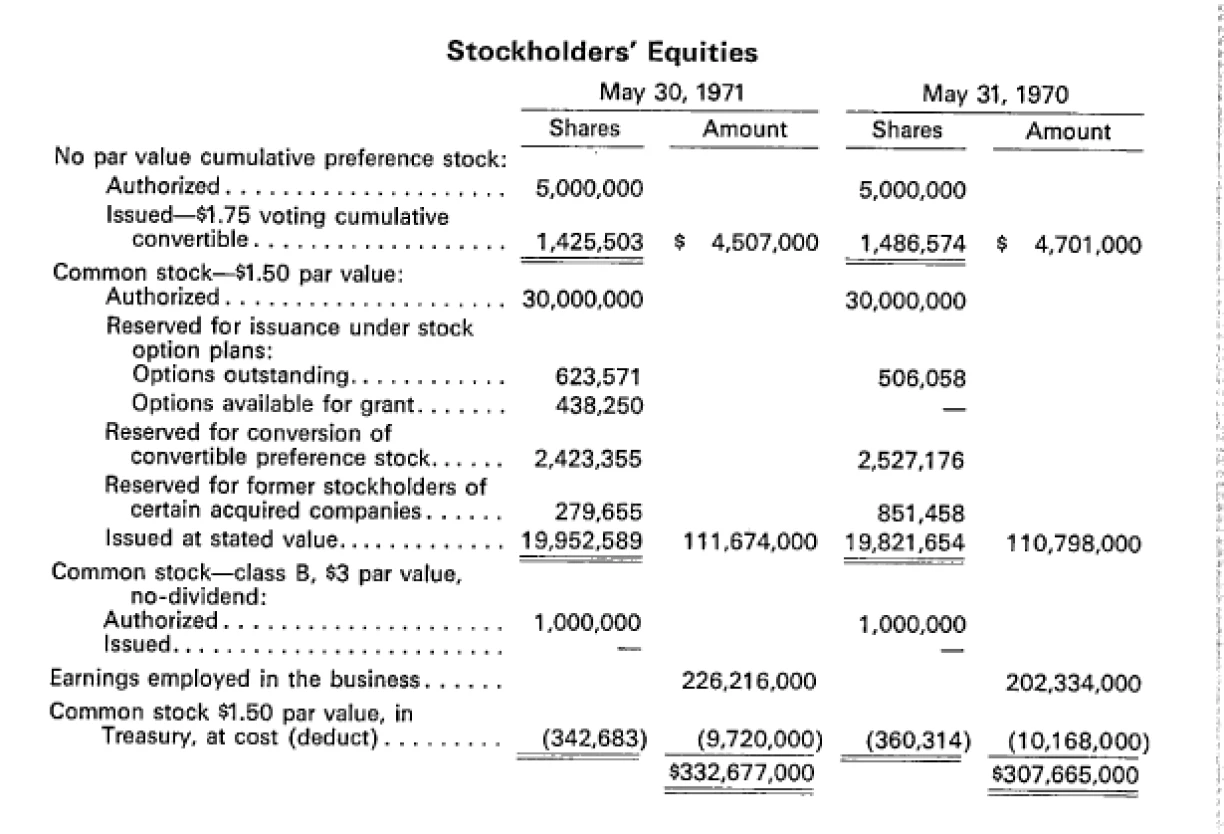
Image 2. An example of tables in our dataset
In our evaluation of table extraction performance, we utilized four key metrics to assess the fidelity of the extracted data against the ground truth. These metrics offer granular insights into different structural components of a table, from titles to individual cells.
- Title accuracy: Evaluates whether the extracted title matches the ground truth title after normalization (e.g., trimming whitespace, case normalization). This ensures the correct identification of the table’s contextual label.
Scoring: It is a binary metric—a score of 1 is awarded for an exact match and 0 otherwise. - Header accuracy: Headers typically represent the column names of a table. This metric checks the extracted header list against the ground truth. It quantifies how accurately column labels have been captured, including their order and completeness.
Scoring: Header accuracy is calculated by comparing each element in both lists and computing the ratio of matching elements to the maximum number of items in either list. - Row accuracy: Measures how many ground truth rows appear in the extracted table, regardless of order. This reflects the completeness of data extraction at the row level.
Scoring: For each row in the ground truth, the evaluator checks for an exact match in the extracted rows. The score is the fraction of matching ground truth rows. - Cell accuracy: This metric provides a fine-grained comparison of the table content by evaluating individual cell matches. Cell accuracy captures the precision of data extraction at the most granular level.
Scoring: It counts the number of matching cells between the extracted and ground truth tables. Extra or missing cells are treated as mismatches. The final score is the ratio of matching cells to total cells assessed.
To provide a single summary metric, we compute the average tabular score as the simple arithmetic mean of the four metrics: title accuracy, header accuracy, row accuracy, and cell accuracy. This average provides a holistic view of table extraction quality.
When implementing Agentic Document Extraction, leveraging the API effectively to extract structured information from visually complex documents is essential. Using your preferred tools’s built-in features to handle errors efficiently, including automatic retries for rate-limiting issues and intermittent HTTP errors.
Configuration and security practices
Proper configuration and secure handling of credentials are vital for reliable and safe API usage:
- Securely set your API key as an environment variable or store it within a .env file.
- Use the library’s Settings object for streamlined configuration management.
- Customize configuration options easily through environment variables or .env files to enhance flexibility and security.
These practices protect sensitive data and help maintain robust operations.
Error handling and optimization in ADE
The Agentic Document Extraction tools offer strong error-handling capabilities to optimize reliability and performance:
- They automatically manage rate limits and intermittent HTTP errors through built-in retries.
- They prevent rate-limit-related errors by adhering to API usage guidelines.
- Segmenting large PDF documents into manageable batches efficiently enhances processing speed and stability.
These strategies minimize downtime and ensure optimal performance, even under demanding conditions.
FAQ
What is agentic document extraction, and how does it differ from traditional data extraction methods?
Agentic document extraction is an advanced approach to extracting structured data from documents, focusing not only on textual content but also on understanding visual elements such as charts, tables, images, and layout. Unlike traditional text extraction, which relies on identifying text in a linear format, agentic document extraction considers the visual context and visual grounding to provide more accurate extractions. It interprets both the original document’s content and its layout, including input fields, form fields, bounding box, and other visual markers. This approach makes it especially useful for processing multiple documents, such as policy documents, financial reports, and medical forms, which often contain a mix of text and visual data. The agentic framework allows for the extraction of key clauses, tables, images, and charts, enabling businesses to automate document intelligence workflows more effectively.
To integrate agentic document extraction into your current systems, you can use the agentic document extraction API. This API provides a straightforward way to automate the extraction of data from various types of documents, including PDF files, medical forms, and financial reports. By obtaining an API key, you can call the API to process documents and extract valuable information such as longer documents, lab results, and policy documents. The API will return extracted data in a structured format like markdown representation, including chunk id, form fields, and other relevant context. It supports processing multiple documents simultaneously, helping businesses streamline their workflows. Whether you’re dealing with account details, tables, or images, the API is designed to handle complex document layouts and adapt to your needs. The integration also supports log management, allowing you to track the performance and accuracy of the extraction processes.
Using agentic document extraction for longer documents, such as financial reports or policy documents, offers numerous benefits. By leveraging visual elements and understanding layout, agentic extraction can accurately parse complex documents that span multiple pages, breaking them down into structured data. This is particularly useful for extracted data that includes key financial metrics, tables, and charts. Traditional text extraction methods may struggle with these formats, but agentic document extraction can handle the intricacies of visual context, allowing you to extract data from multiple documents simultaneously. For example, when processing financial reports, the system can identify relevant key clauses and input fields, ensuring accurate data extraction even from documents with intricate formatting. This level of precision helps improve accuracy and reduces manual labor, speeding up decision-making and workflow automation.




{kind=link}