
Explanation of Vision Transformer with implementation | by Hiroaki Kubo | Nov, 2024
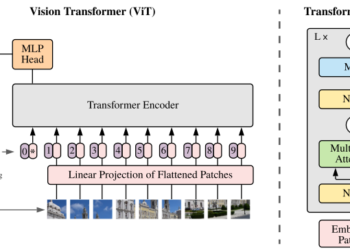
First, we reshape the picture right into a sequence of flattened 2D patches. The code is as follows. image_size means ...

First, we reshape the picture right into a sequence of flattened 2D patches. The code is as follows. image_size means ...


