

Startup Gimlet Labs is solving the AI inference bottleneck in a surprisingly elegant way
Stanford adjunct professor and successfully exited founder Zain Asgar just raised an $80 million Series A for a startup that ...

Stanford adjunct professor and successfully exited founder Zain Asgar just raised an $80 million Series A for a startup that ...

Modal Labs, a startup specializing in AI inference infrastructure, is talking to VCs about a new round at a valuation ...

A weekly curated update on data science and engineering topics and resources.Continue reading on Medium » Source link
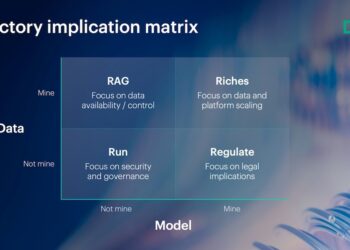
Reaching the next stage requires a three-part approach: establishing trust as an operating principle, ensuring data-centric execution, and cultivating IT ...

In this article, you will learn how to add both exact-match and semantic inference caching to large language model applications ...

Press enter or click to view image in full sizeWhen OpenAI and Meta rolled out new LLMs in early 2025, ...


