

When testing a classification downside, there are two key classes to contemplate: precise and predicted.
- Precise refers back to the true label of a check pattern, matching real-world circumstances (e.g., a textual content message is SPAM).
- Predicted refers back to the output generated by the machine studying mannequin (e.g., the mannequin predicts SPAM).
After testing, the outcomes will fall into one in all 4 lessons:
1. Accurately categorised to class 1: True HAM
2. Accurately categorised to class 2: True SPAM
3. Incorrectly categorised to class 1: False HAM
4. Incorrectly categorised to class 2: False SPAM

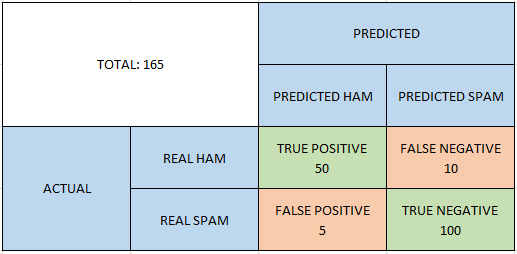
- True Constructive (TP): When the precise HAM is appropriately predicted as HAM by the mannequin.
- False Unfavorable (FN): When the precise HAM is incorrectly predicted as SPAM.
- False Constructive (FP) (Sort 1 Error): When the precise SPAM is incorrectly predicted as HAM.
- True Unfavorable (TN) (Sort 2 Error): When the precise SPAM is appropriately predicted as SPAM.
Utilizing the confusion matrix above, let’s calculate the accuracy fee and error fee.
- Accuracy Price: This measures how typically the mannequin makes appropriate predictions. It’s calculated as:

- Error Price: This measures the frequency of incorrect predictions. It’s calculated as:

In abstract, the accuracy fee tells us how properly the mannequin performs general, whereas the error fee highlights how typically the mannequin makes incorrect predictions.




{kind=link}