

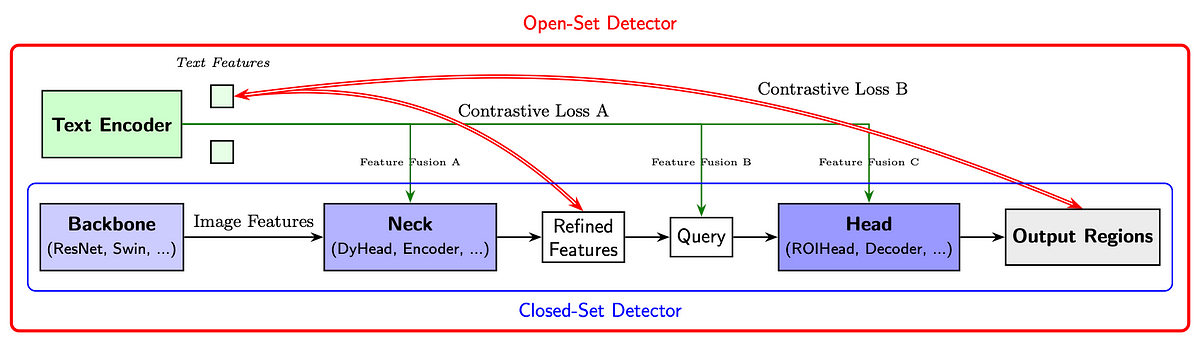

Have you ever wondered if computers could learn to detect any object in an image, even if that object has never been seen during training? That is precisely the challenge that “open-set object detection” aims to solve. In a new 2024 ECCV publication that has already amassed over 1700 citations — an astounding number that highlights the urgency and excitement around this research — a large and diverse team of scientists presents “Grounding DINO: Marrying DINO with Grounded Pre-training for Open-Set Object Detection.” This work could well be a milestone in how we train computers to see and understand the visual world.
Why Do We Even Care About Open-Set Object Detection?
Traditionally, computer vision models detect objects from a fixed, “closed” set of categories such as cats and tables. While this is useful, real-world scenarios are rarely so tidy. Think of self-driving cars that must identify everything from traffic cones to errant beach balls, or medical imaging systems that must spot anomalies no one has ever formally labeled. To meet these open-world challenges, researchers have been adding more sophisticated language understanding components to detection systems, so the models can be guided by everyday words or phrases instead of narrow, pre-defined class labels. This shift promises…




{kind=link}