

DATA STORIES | FINANCE | KNIME ANALYTICS PLATFORM
Learn how to detect fraud using a Random Forest model
This is part of a series of articles to show you solutions to common finance tasks related to financial planning, accounting, tax calculations, and auditing problems all implemented with the low-code KNIME Analytics Platform.
Credit card fraud detection stands out as an ongoing challenge to accurately identify all new fraud patterns. Datasets containing fraud examples are rare, and when they do exist, they often include a limited number of outdated cases. This scarcity makes fraud detection particularly challenging, as it must continuously adapt to the evolving tactics of fraudsters.
There are two approaches to fraud detection:
- Classic machine learning based predictions, when your dataset contains enough fraud examples
- Outlier detection based techniques, when your dataset does not contain a sufficient number of fraud examples
The dataset that we will use contains a small percent of fraudulent transactions. Based on these examples, we will implement the classic machine-learning based approach for fraud detection for this article.
In the next couple articles, we will show how to implement fraud detection algorithms using outlier detection based techniques.
Whatever your data situation is, this series will show you how KNIME Analytics Platform offers a low-code solution for this problem. It can enable financial teams to automate data intake from various sources and leverage advanced analytics to detect fraudulent transactions, without the need for a coding background.
In this article on fraud detection, you’ll learn how to use the Random Forest supervised learning algorithm to help identify fraudulent transactions. Watch the video for an overview.
Credit card transactions can essentially be divided into two categories: legitimate and fraudulent. The task at hand is to accurately identify and flag fraudulent transactions to ensure that a small minority of flagged transactions are legitimate.
The process of fraud detection often involves several manual and automated steps to analyze transaction patterns, customer behavior, and other relevant factors. For our purposes, we will only focus on the automation part of detection by training a model on a labeled dataset and applying it to a new transaction to simulate incoming data from an outside data source.
We use a popular dataset available from Kaggle called Credit Card Fraud Detection. This dataset is composed of real, anonymized transactions made by credit cards in September 2013 by European cardholders. It includes 284,807 transactions over two days, containing 492 fraudulent transactions. The dataset represents a severe class imbalance between the ‘good’ (0) and ‘frauds’ (1), where ‘frauds’ account for only 0.172% of the data.
The dataset contains 31 columns:
A key feature needed for our training is ‘Class’ as we need labeled data for a supervised training algorithm.
The process for creating our classification model follows the steps below. Even if there is data coming from multiple sources, the overall process does not change:
- Create/import a labeled training dataset
- Partition the data
- Train the model
- Evaluate model performance
- Import the new, unseen transactions
- Deploy the model and feed the new transactions in
- Notify if any fraudulent transactions are classified.
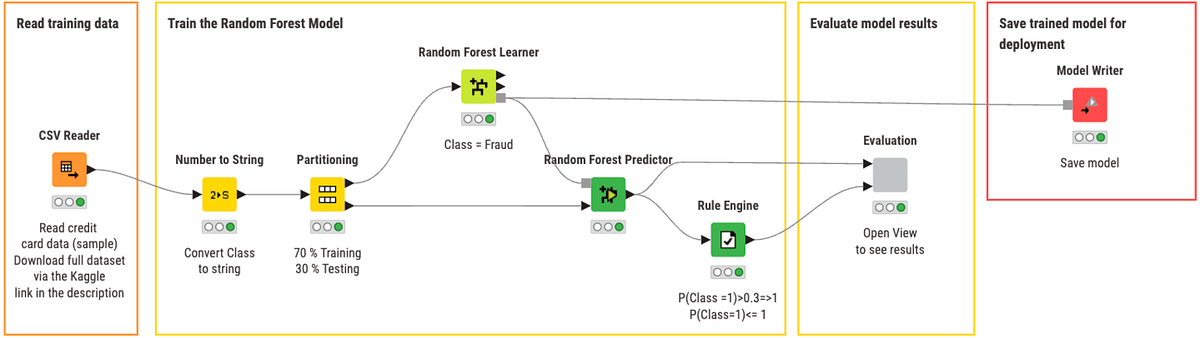
All workflows used in this article are available publicly and free to download on the KNIME Community Hub. You can find the workflows on the KNIME for Finance space under Fraud Detection in the Random Forest section.
The first workflow covers training our model. You can view and download the training workflow Random Forest Model Training from the KNIME Community Hub.




{kind=link}