

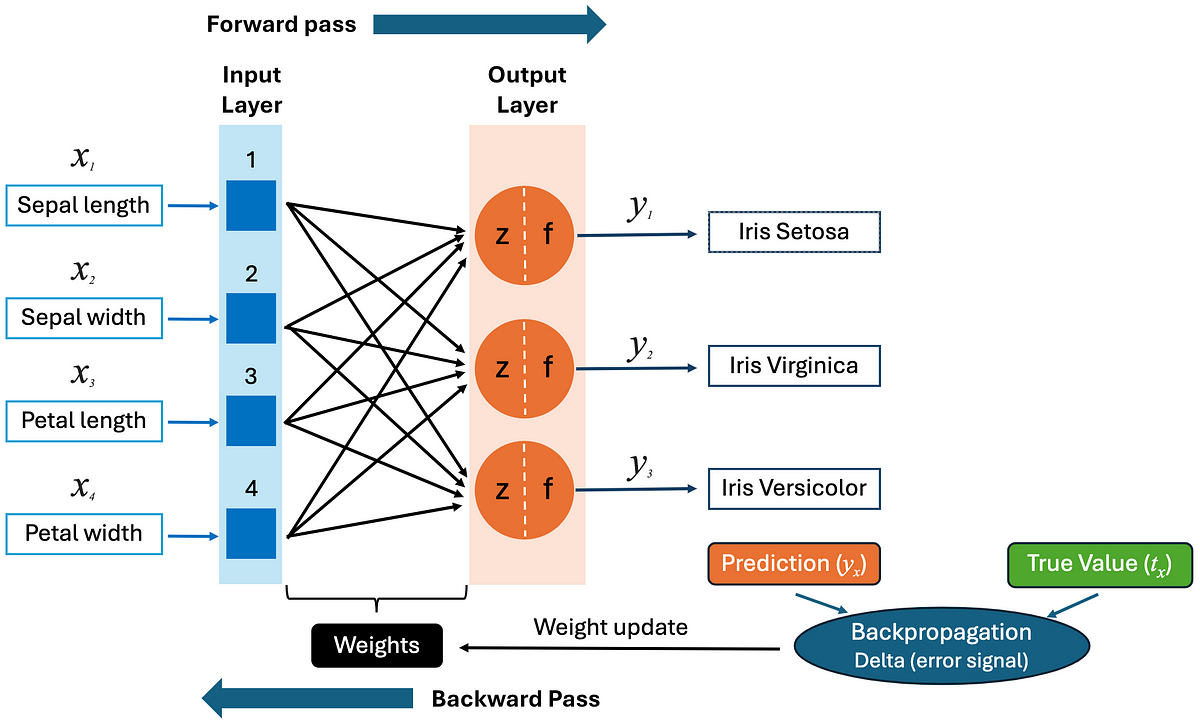
Machine Learning is everywhere, and most of us begin our journey using Python libraries like Scikit-learn, TensorFlow, or PyTorch. But what if we built a neural network from scratch, without any libraries, just C++ ?
In this article, we’ll build a simple neural network in C++ to classify flowers from the famous Iris dataset. This is a beginner-friendly guide that will help you understand the fundamentals of machine learning.
The Iris dataset is one of the most popular datasets in machine learning. It contains 150 samples of iris flowers, with 4 features each:
- Sepal length (in cm)
- Sepal width (in cm)
- Petal length (in cm)
- Petal width (in cm)
Each sample is labeled with one of three species:
- Iris Setosa
- Iris Versicolour
- Iris Virginica
The goal is to build a classifier that predicts the species based on the four measurements.
Input & Iris Class
The Iris class extends from an abstract Input class. It parses the data file, extracts the 4 features and converts the species label into a number:
- ‘0’ for Setosa
- ‘1’ for Virginica
- ‘2’ for Versicolor
The constructor reads and splits the input string by commas, then converts each feature to double and stores the label as a char.
Activation functions
Activation functions are critical in neural networks because they introduce non-linearity, allowing the model to learn complex patterns in data. Without them, a neural network would be equivalent to a linear regression model, no matter how many layers it had.
We define two activation functions in our implementation:
Tanh (hyperbolic tangent) :
- Output range: (-1, 1)
- It’s often used in hidden layers of neural networks.
A hyperbolic function that is written in symbol Tanh and defined as the following :
The derivate of Tanh (Hyperbolic Tangent) Function is defined as the following :
Sigmoid
- Output range: (0, 1)
- It compresses input values into a range between 0 and 1, making it suitable for binary classification.
- However, sigmoid suffers from vanishing gradients, especially with very high or very low inputs.
The sigmoid function is defined as :
The derivative is known as the density of the logistic distribution:
Perceptron
A perceptron is the most fundamental building block of a neural network. It was introduced in 1958 by Frank Rosenblatt as a model of how biological neurons work. It performs binary classification by taking several input values, multiplying each by a corresponding weight, summing them up with a bias, and applying an activation function to decide the output.

Mathematically, it looks like this:

x1toxnare input features.w1townare learned weights.w0is the bias (or threshold).- σ is a nonlinear function like sigmoid or tanh.
The Perceptron class in the code maintains an array of weights and uses either a Sigmoid or Tanh function to produce its output.
Each perceptron is associated with one label. For the Iris dataset, we use 3 perceptrons — one for each class (Setosa, Virginica, or Versicolor).
Each perceptron receives an activation function pointer during initialization. This keeps the implementation flexible, allowing easy switching or testing of new activation functions. Choosing the right activation function can significantly affect the model’s ability to learn effectively.

Neural Network (NN1)
Our NN1 class is a basic one-layer network designed for multiclass classification. In our example we have an array of 3 perceptrons. As we said before each one dedicated to recognizing one specific class in the Iris dataset: Setosa, Virginica, Versicolor. During evaluation, we compute the forward pass of all perceptrons and select the one with the highest score.
Forward Pass
The forward pass is the first step in evaluating a neural network. Conceptually, it refers to the process where input data flows through the network layer by layer to generate a prediction.
As we said before in “Perceptron” part, at each neuron (or perceptron), the input features (sepal and petal dimensions) are multiplied by their respective weights, a bias is added, and the result is passed through an activation function to determine the output. This process is repeated through all layers (in our case, just one output layer) until a final prediction is made. The result produces a score indicating how likely the input belongs to its assigned class.
Here’s the implementation of the forward pass in our Perceptron class:
Backpropagation
Backpropagation is the core algorithm that allows neural networks to learn from their mistakes. It’s a supervised learning technique that adjusts weights in the network to minimize the error between the predicted output and the true label.
Conceptually, backpropagation consists of two main steps:
- Forward Pass: First, the input data is passed through the network to compute the predicted output.
- Backward Pass: Then, the error is calculated by comparing the predicted output to the true label. This error is propagated backward through the network to compute how much each weight contributed to the total error.
We compute the delta (error signal) using the derivative of the activation function:

Where:
f'(sum)is the derivative of the activation function evaluated at the weighted sum (before activation).y(x)is the predicted output.t(x)is the true label (converted into 0 or 1 depending on whether this perceptron represents the correct class).
Once we have the delta, we update each weight using the gradient descent rule:

w_iis the i-th weight.muis the learning rate.x_iis the i-th input feature.
In code, this logic is implemented in Perceptron::backpropagation()
Finally the the training loop will be in NN1::train() function
In this section, we’ll go through the two main components that bring everything together: the Training class and the Main class.
Training
The Training class is responsible for iterating over the dataset, adjusting the neural network’s weights, and applying the backpropagation algorithm to minimize the error in the predictions.
Here, the class Training works with the Neural Network (NN1) and a dataset (Iris dataset in our case). The class accepts a neural network object, trains it by adjusting the weights based on the provided dataset, and performs evaluations to measure how well the model performs.
The training class is designed to be flexible and can work with any dataset (like the Iris dataset) and any neural network structure (in our case, NN1 with one hidden layer).
Main
The Main class performs the following tasks:
- Loading the Dataset: In the main function, we load the Iris dataset, which contains labeled examples of flowers, it’s our input.
- Testing the Neural Network: We create an instance of the neural network (
NN1), initialize it with specific parameters (like the number of inputs and perceptrons), and test it with both the Sigmoid then the Tanh activation functions. - Training and Evaluating: The main class invokes the Training class to perform training and evaluation. It runs the neural network for a set number of epochs and evaluates the network’s performance by comparing predicted outputs against the expected labels from the dataset.
In this article, we have built a simple neural network from scratch using C++ to classify the Iris dataset. We’ve defined the Perceptron, NN1 (Neural Network), Activation functions, and Training classes, each playing a specific role in the architecture and learning process.
There are a a lot of ways we could improve its performance and versatility like:
- Multiple Layers: adding additional hidden layers (making it a multi-layer perceptron, or MLP) can significantly.
- Different Activation Functions: We’ve used Sigmoid and Tanh activation functions in this example. However, there are other activation functions such as ReLU (Rectified Linear Unit) that can help overcome issues like the vanishing gradient problem, which often occurs with sigmoid or tanh functions in deeper networks.




{kind=link}